Mục lục nội dung
Tìm hiểu Apache Hadoop là gì ?
Hadoop là một dạng framework, đơn cử là Apache. Apache Hadoop là một mã nguồn mở được cho phép sử dụng những distributed processing ( ứng dụng phân tán ) để quản trị và tàng trữ những tệp tài liệu lớn. Hadoop vận dụng quy mô MapReduce trong hoạt động giải trí giải quyết và xử lý Big Data .Vậy MapReduce là gì ? MapReduce vốn là một nền tảng được Google tạo ra để quản trị tài liệu của họ. Nhiệm vụ của MapReduce là tiếp đón một khối lượng tài liệu lớn. Sau đó sẽ triển khai tách những tài liệu này ra thành những phần nhỏ theo một tiêu chuẩn nào đó. Từ đó sẽ sắp xếp, trích xuất những tệp tài liệu con mới tương thích với nhu yếu của người dùng. Đây cũng là cách mà thanh tìm kiếm của Google hoạt động giải trí trong khi tất cả chúng ta sử dụng hằng ngày .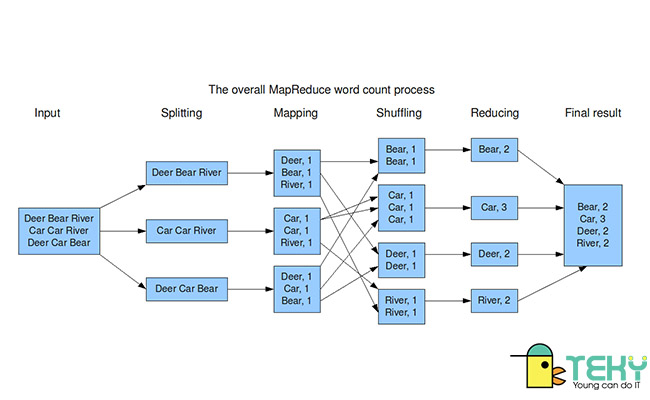
Còn bản thân Hadoop cũng là một dạng công cụ mẫu giúp phân tán dữ liệu theo mô hình như vậy. Cho nên MapReduce được sử dụng như một nền tảng lý tưởng của Hadoop. Về cơ bản, Hadoop sẽ giúp người dùng tổng hợp và xử lý một lượng thông tin lớn trong thời gian ngắn bằng MapReduce.
Còn với công dụng tàng trữ, Hadoop sẽ dùng HDFS. HDFS là gì ? Nó được biết đến như một kho thông tin có độ truy vấn nhạy và ngân sách thấp .Hadoop được tăng trưởng nên từ ngôn từ Java. Tuy nhiên nó vẫn tương hỗ một số ít ngôn từ lập trình khác như C + +, Python hay Pearl nhờ chính sách streaming .
Kiến trúc của Hadoop là gì ?
Vì sử dụng cùng lúc MapReduce và HDFS nên Hadoop sẽ có cấu trúc của cả 2 loại này. Hadoop thừa kế cấu trúc node từ HDFS. Cụ thể, một cụm Hadoop sẽ gồm có 1 master node ( node chủ ) và rất nhiều worker / slave node ( node nhân viên cấp dưới ). Một cụm cũng gồm có 2 phần là MapReduce layer và HDFS layer. Master node gồm có JobTracker, TaskTracker, NameNode, và DataNode. Còn Worker / Slave node gồm có DataNode và TaskTracker. Trong một số ít trường hợp, Worker / Slave node được dùng để làm dữ liệu hoặc thống kê giám sát .Hadoop Apache gồm có 4 module khác nhau. Sau đây sẽ là trình làng chi tiết cụ thể về từng loại .
Hadoop Common
Hadoop Common được dùng như một thư viện tàng trữ những tiện ích của Java. Tại đây có những tính năng thiết yếu để những modules khác sử dụng. Những thư viện này mang đến mạng lưới hệ thống file và lớp OS trừu tượng. Song song với đó, nó cũng tàng trữ những mã lệnh của Java để thực thi quy trình khởi động Hadoop .
Hadoop YARN – Hadoop là gì ?
Phần này được dùng như một framework. Nó tương hỗ hoạt động giải trí quản trị thư viện tài nguyên của những cluster và thực thi chạy nghiên cứu và phân tích tiến trình .Hiểu rõ cách hoạt động giải trí của những modules sẽ giúp bạn nắm rõ khái niệm Hadoop là gì .
Hadoop Distributed File System ( HDFS )
Một trong những yếu tố lớn nhất của những mạng lưới hệ thống nghiên cứu và phân tích Big Data là quá tải. Không phải mạng lưới hệ thống nào cũng đủ khỏe để hoàn toàn có thể tiếp đón một lượng thông tin khổng lồ như vậy. Chính do đó, trách nhiệm của Hadoop Distributed File System là phân tán cung ứng truy vấn thông lượng cao giúp cho ứng dụng chủ. Cụ thể, khi HDFS nhận được một tệp tin, nó sẽ tự động hóa chia file đó ra thành nhiều phần nhỏ. Các mảnh nhỏ này được nhân lên nhiều lần và chia ra tàng trữ tại những sever khác nhau để phân tán sức nặng mà tài liệu tạo nên .
Như đã nói ở trên, HDFS sử dụng cấu trúc master node và worker/slave node. Trong khi master node quản lý các file metadata thì worker/slave node chịu trách nhiệm lưu trữ dữ liệu. Chính vì thế nên worker/slave node cũng được gọi là data node. Một Data node sẽ chứa nhiều khối được phân nhỏ của tệp tin lớn ban đầu. Dựa theo chỉ thị từ Master node, các Data node này sẽ trực tiếp điều hành hoạt động thêm, bớt những khối nhỏ của tệp tin.
Hadoop MapReduce
Module này hoạt động giải trí dựa trên YARN trong việc giải quyết và xử lý những tệp tài liệu lớn. Hadoop MapReduce được cho phép phân tán tài liệu từ một sever sang nhiều máy con. Mỗi máy con này sẽ nhận một phần tài liệu khác nhau và triển khai giải quyết và xử lý cùng lúc. Sau đó chúng sẽ báo lại hiệu quả lên sever. Máy chủ tổng hợp thông tin lại rồi trích xuất theo như nhu yếu của người dùng . Cách thực thi theo quy mô như vậy giúp tiết kiệm ngân sách và chi phí nhiều thời hạn giải quyết và xử lý và cũng giảm gánh nặng lên mạng lưới hệ thống. Chức năng của sever là quản trị tài nguyên, đưa ra thông tin, lịch trình hoạt động giải trí cho những máy trạm. Các máy trạm sẽ thực thi theo kế hoạch được định sẵn và gửi báo cáo giải trình tài liệu lại cho sever. Tuy nhiên đây cũng là điểm yếu của mạng lưới hệ thống này. Nếu sever bị lỗi thì hàng loạt quy trình sẽ bị ngừng lại trọn vẹn .
Cách thực thi theo quy mô như vậy giúp tiết kiệm ngân sách và chi phí nhiều thời hạn giải quyết và xử lý và cũng giảm gánh nặng lên mạng lưới hệ thống. Chức năng của sever là quản trị tài nguyên, đưa ra thông tin, lịch trình hoạt động giải trí cho những máy trạm. Các máy trạm sẽ thực thi theo kế hoạch được định sẵn và gửi báo cáo giải trình tài liệu lại cho sever. Tuy nhiên đây cũng là điểm yếu của mạng lưới hệ thống này. Nếu sever bị lỗi thì hàng loạt quy trình sẽ bị ngừng lại trọn vẹn .
Cách hoạt động giải trí của Hadoop là gì ?
Giai đoạn 1
Người dùng hoặc ứng dụng sẽ gửi một job lên Hadoop để nhu yếu giải quyết và xử lý và thao tác. Job này sẽ đi kèm những thông tin cơ bản như : nơi tàng trữ tài liệu input và output, những java class chứa những dòng lệnh thực thi, những thông số kỹ thuật thiết lập đơn cử .
Giai đoạn 2
Sau khi nhận được những thông tin thiết yếu, sever sẽ chia khối lượng việc làm đến cho những máy trạm. Máy chủ sẽ thực thi theo dõi quy trình hoạt động giải trí của những máy trạm và đưa ra những lệnh thiết yếu khi có lỗi xảy ra .
Giai đoạn 3
Các nodes khác nhau sẽ thực thi chạy tác vụ MapReduce. Nó chia nhỏ những khối và thay phiên nhau giải quyết và xử lý tài liệu. Khi Hadoop hoạt động giải trí, nó sử dụng một tệp tin nền làm địa chỉ thường trú. Tệp tin này hoàn toàn có thể sống sót trên 1 hoặc nhiều sever khác nhau .
Ưu điểm của Hadoop là gì ?
Hadoop được cho phép người dùng nhanh gọn kiểm tra được tiến trình hoạt động giải trí của những phân tán. Nhờ vào chính sách giải quyết và xử lý cùng lúc của những lõi CPU, một lượng lớn tài liệu được phân phối xuyên suốt liên tục và không bị gián đoạn do quá tải . Hadoop không bị ảnh hưởng tác động bởi chính sách chịu lỗi của fault-tolerance and high availability ( FTHA ). Nó có năng lực giải quyết và xử lý lỗi riêng nhờ những thư viện được phong cách thiết kế để phát hiện lỗi ở những lớp ứng dụng. Chính do đó, khi không may có lỗi xảy ra, Hadoop sẽ nhanh gọn giải quyết và xử lý nó trong thời hạn ngắn nhất nhờ chính sách dữ thế chủ động của mình .
Hadoop không bị ảnh hưởng tác động bởi chính sách chịu lỗi của fault-tolerance and high availability ( FTHA ). Nó có năng lực giải quyết và xử lý lỗi riêng nhờ những thư viện được phong cách thiết kế để phát hiện lỗi ở những lớp ứng dụng. Chính do đó, khi không may có lỗi xảy ra, Hadoop sẽ nhanh gọn giải quyết và xử lý nó trong thời hạn ngắn nhất nhờ chính sách dữ thế chủ động của mình .
Một ưu điểm nữa của Hadoop là khả năng triển khai rất nhiều master-slave song song để xử lý các phần khác nhau. Vì có nhiều server master nên công việc sẽ công bị trì hoãn dù không may có một master bị lỗi.
Xem thêm: LGBTQI+ có nghĩa là gì?
Và ở đầu cuối, do Hadoop được kiến thiết xây dựng từ ngôn từ Java nên nó có năng lực thích hợp với rất nhiều nền tảng và hệ quản lý và điều hành khác nhau, từ Window, Linux đến MacOs …
Mời bạn đọc tìm hiểu thêm thêm : Gitignore File là gì ?
Kết luận
Vừa rồi Teky đã mang đến nhiều thông tin hữu dụng xoay quanh chủ đề Hadoop là gì. Với những liệt kê rất đầy đủ từ định nghĩa, đặc thù cho đến phương pháp hoạt động giải trí, mong rằng bạn đã hoàn toàn có thể nắm chắc trong tay những kỹ năng và kiến thức về công cụ giải quyết và xử lý Big Data hữu hiệu này. Chúc bạn hoàn toàn có thể nhanh gọn học hỏi được và vận dụng Hadoop thuần thục vào trong việc làm của ban thân nhé !
Source: https://blogchiase247.net
Category: Hỏi Đáp





